I’ve recently begun trying to produce some youtube videos on programming topics that I find interesting. In that interest, I’ve come to use the kdenlive linux video editor 1. Kdenlive is pretty nice and will serve my needs just fine.
One thing I’ve aspired to do is some multi-camera videos. My wife practices a couple kinds of martial arts and I’d love to record some of her test katas from several angles.
Aligning a handful of clips really isn’t that hard to do manually, but since I’m a nerd, I decided to program a utility to do this. It’s a problem that I wanted to implement for years and I’ve finally gotten to it.
Similar to the product PluralEyes, my utility looks at the audio portions of your clips and aligns them based on that. In a nutshell, I compute the cross correlation of all pairs of clips using FFTs and then write a timeline based on the strongest matches.
The end of this post will have more implementation details.
Here is a quick demo
The steps to use it are pretty simple
Step 1 – create an unaligned kdenlive project
First, create a kdenlive project that contains all of the desired clips in the desired tracks as below (click for larger image). Note that the clock in the multiple views show different times. This demo project has three different cameras (an S5, HTCM8, and motorola something) in addition to a cheap Sony voice recorder and a Sony PCM-M10
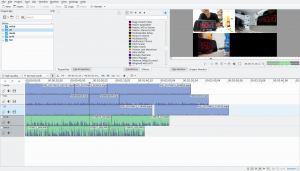
Here’s the fancy rig I used. It’s for creating some 360 style VR videos. I have some scripting for merging stuff together using Hugin, but I haven’t been satisfied with the results yet.

Step 2 – run the utility
A binary of the utility can be found on my github. You can also find the source code for it.
To run it is easy. In the example below, my project is called easydump, because it’s just an easy dump of all the clips:
[code]
./sync_kdenlive video_and_voice_recorders/easydump.kdenlive
[/code]
It will create the file easydump_aligned.kdenlive. It also creates easydump_aligned_aligned0.wav which is a wav file with as many channels as clips.
The demo is about 4.5 minutes and the utility runs in ~10seconds on my Skylake with 16GB. 2 Run time will scale linearly in the length of your longest clip and quadratic in the number of clips. So far, I’ve made little/no attempt to optimize it beyond using FFTs.
This utility is for my own benefit/enjoyment/curiosity. If you have any interest in it, please comment. If you tried to run it and it didn’t work, please comment. If you tried it and it did work, please comment. If I get no comments, I’ll assume no one cares and will make no effort to make it better.
Of course, the easydump part isn’t hardcoded. It’s just the file name that I chose for this experiment.
Step 3 – load the updated project file into kdenlive
Step 2 generated a easydump_aligned.kdenlive. Load it into kdenlive. In the picture below, note that the clocks show the same time.
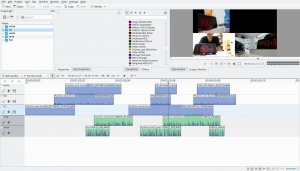
Here’s the result. From listening to the audio of it, I’d say it worked pretty well:
So how’s it work?
The core idea is something that I learned many moons ago, when I took 6.003 – signals and systems. A playlist of the 2011 lectures can be found here.
In particular, this lecture about convolution:
Convolution or the variant of it cross-correlation that I use in the utility is basically that act of sliding one signal along another, multiply the two, and taking the area of the result. A large area means lots of similarity. Smaller area means less.
If you were to just compute the cross correlation directly, you’d have a lot of computation to do. Thankfully, there was a guy named Fourier who found a way to compute this in the frequency domain. This coupled with the Fast Fourier Transform enables me to to cross correlations on WAV files pretty quickly.
Here are the required steps:
- compute the discrete fourier transform of each of your wav files. The length of each result should be equal to the max of the lengths of the two wavs.
- piecewise, multiply the first by the complex conjugate of the second
- compute the inverse transform of the result of those multiplies.
Here is what you get with you take two sine waves, shifted relative to each other. The two two waveforms are the two input sines. The bottom two are the real and imaginary components of the cross correlation. The source code for this experiment can be found here on my github.
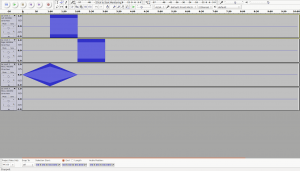
Note that this technique works for any kind of data. Spatial/visual works too. I’ve had thoughts of implementing a jigsaw puzzle solver this way.
Try it with your own waves
I have a compiled (for ubuntu linux) binary of a utility that takes two waves and writes a wave showing the cross correlation. It can be found here. To invoke it:
[code]
./sync_wavs file2.wav file1.wav true
[/code]
If you omit the “true” argument, you’ll get just the aligned channels. In this case, I added true to tell sync_wavs to include the cross-correlation as the third and fourth channels. Note the peak location corresponds to the beginning of the second channel.
Attribution of libraries I used
Very few real programming projects are implemented entirely from scratch and this one is no different. The external libraries I used are:
FFTW This library implements the fourier transform parts. In addition to its excellent tutorial, I have a couple simple programs that I used in the lead up to this project.
TinyXML2 This library implements the xml read/write functions. I have a lot of experience using LibXML2’s perl interface. LibXML2 is excellent but there are some areas where it makes me do more of the work than I care for. TinyXML2 is easier to use in most ways. The output xml is nicely formatted by default. Adding text and new elements is a bit quicker to implement. The main thing missing TinyXML2 is XPATH support. Using the visitor methods sort of makes up for this.
BOOST. It’s hard for me not to use boost these days. In particular, I use:
ffmpeg I don’t use this in the code directly. The code does call ffmpeg to extract wav files of the same samplerate from each of the clips.
Some additional implementation details
I have found that downsampling the audio of each clip to 5k samples/sec works fine. This is important because the longer the fourier transform, the longer the runtime.
When taking the ffts and iffts, you need to double the length of the input data but padding with zeros (ie, the first half is your wav, the second is silence). This is important in knowing the relative order and offset of any pair of clips. The way the cross-correlation works, if you have a negative offset, the peaks will show up in the second half of the transform data. At the same time, what happens if one clip begins near the end (past halfway) of the other? To sidestep this, I simply doubled the data lengths. 3
In the utility, I compute the cross correlation for all pairs of audios. Some of those pairs will correlate better than other and some don’t correlate at all (since they don’t overlap). Here’s the method I’ve found to work for me:
- compute the mean/average and standard deviation of the cross-correlation result.
- find the peak value
- order the peaks of all the pairs by ordering by the number of standard deviations above the mean/average. For pairs that should correlate (they overlap), the peaks tend to be at least 15 standard deviations above the mean.
I actually have a version of Movie Studio Platinum, which I paid for some years ago. The problem is that I use windows less and less ↩
I imagine that anyone doing video editing will need/want/have a machine that it also pretty beefy. I’m using the graphics stuff built into the Skylake. ↩
I imagine there’s a way to do this without doubling but I don’t know the math well enough. If you do know, please let me know ↩
2 responses to “Automatically aligning multiple video/audio clips in kdenlive”
Hi I would like to get this working on my system, I get this message
temu@temu-ubuntustudio:~$ ./sync_kdenlive /kdenlive/2017_25ac.kdenlive
getting track resources
mean 0 variance 0 max -9223372036854775808 min 9223372036854775807
need fft size of 0
time for all ffts 1.6e-06
time for all pairs correlations 1.88e-06
num timelines 0
temu@temu-ubuntustudio:~$
Linux machine detail
Linux temu-ubuntustudio 4.10.0-40-lowlatency #44~16.04.1-Ubuntu SMP PREEMPT Thu Nov 9 17:36:05 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
Kdenlive version 17.04.3
It looks like it’s not finding an video tracks in the kdenlive file.
If you put the relevant files somewhere I can access (google drive, perhaps or dropbox), I’d be happy to take a look. mail me the location. mail@mmccoo.com